then
Bloom filters
-
conceived by Burton Howard Bloom in 1970
-
bit array that answers if element is in the set
-
false positives are possible
-
false negatives are not - answer "NO" is always reliable
-
-
proposed for use in the web context by Johannes Marais and Krishna Bharat for finding pages with associated comments in 1997
-
possible operations: adding and querying/testing
-
used in Big Table, HBase, Cassandra, Squid web proxy and BitCoin wallet synchronization.
|
Important
|
Great, because
Quickly gives certain NO to "is it there" question. The larger your data set is, the more expensive it is to reach it and pull data out (located on disk? on a remote server?), the more useful Bloom filter is. |
How it works
All "is element in set" queries return NO faster and with certainty. YES causes us to go to actual set to fetch element to use it, which may still yield "oops! it’s not really there, you had false information" answer, but at a rate we control (choosing the right number of hash functions).
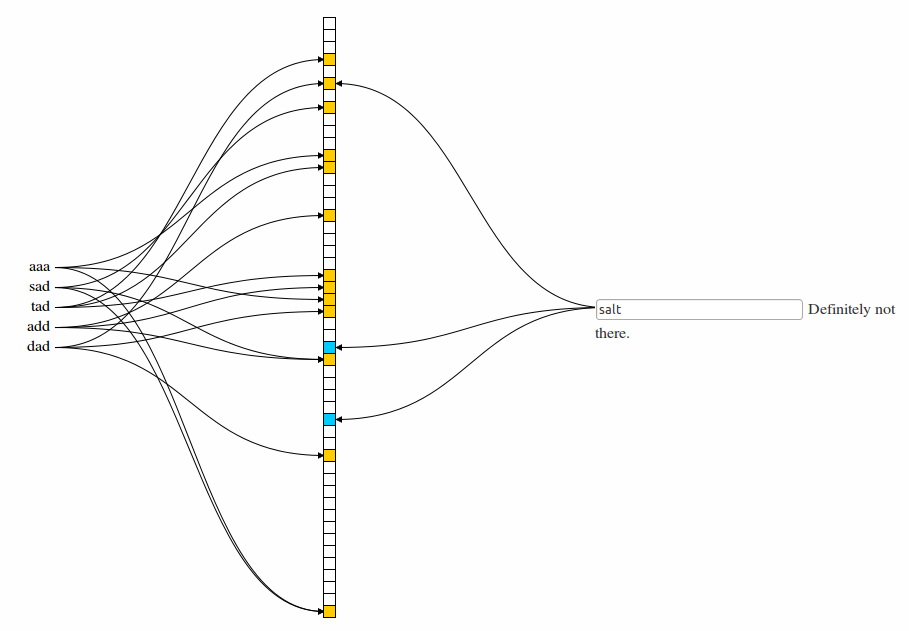
Each word in the set is hashed through all hash functions and resulting bits in Bloom filter are marked yellow (set to 1). When querying for a word, the queried word is hashed and resulting bits are checked - if any is still at 0 (marked blue), the word is NOT in the set (and we don’t need to try retrieving it).
How it’s done
Having a N-element set:
-
Take a bit array of size M
-
Fill it with zeroes
-
Choose appropriate number of hash functions
-
Hash all set elements through all hash functions, setting 1’s in array
-
Implement
addandquery(some call ittest) operations.-
addmakes it possible to add an element to the set -
queryasks the "is it in" question
-
Done. Bloom filter ready. For doubt points read on, or see Tom Hurst’s calculator, referenced in the Math section.

Bit array size?
Irrelevant of N, less than 10 bits per element guarantee a 1% false positive probability. Read this PDF for more.
Assuming
- n
-
number of elements in set (and therefore, filter),
- p
-
probability of false positive,
- m
-
number of bits in filter
m = ceil((n * log(p)) / log(1.0 / (pow(2.0, log(2.0)))));
Appropriate number of hash functions?
|
Warning
|
for toy purposes 2 is enough, though it may well give you false negative! Bill’s simple tutorial (link below) does sometimes, as he chose 2 simple hash functions. |
The more hash functions:
-
the lesser possibility of a false positive
-
the longer adding an element takes
-
the longer each query takes
If
- n
-
number of elements in set (and therefore, filter)
- m
-
number of bits in filter
- k
-
number of hash functions
k = round(log(2.0) * m / n)
Sources
Math
|
Tip
|
I want to play with it!
Great! Use these: |